參考資料
- R 的 ggmap 套件:繪製地圖與資料分佈圖,空間資料視覺化
- 聚類算法:DBScan算法
- Rail occurrence data from January 2004 to present
- 加拿大行政區劃
- 經緯度
前言
-
最近實驗室需要進行專題的展示,而我本身也在準備近期要分享的演講簡報,於是便試著將這一陣子的工作作個簡單的筆記和紀錄。
-
我負責的工作是:將爬蟲抓下來且經過
DBSCAN 演算法分類後的資料,繪製在地圖上並進行資料視覺化。詳細的作法預計會在下一篇說明,現在先找個範例練習。
(一) 先別管資料,單純顯示地圖
1. 顯示基本地圖
我先參考 R 的 ggmap 套件:繪製地圖與資料分佈圖,空間資料視覺化 的內容,將相關的套件安裝好後並加以載入︰
> install.packages("ggmap")
> install.packages("mapproj")
> library(ggmap)
> library(mapproj)
之後,先試著用 ggmap() 抓一個地點來看看:
* 在這裡使用 “加拿大(Canada)” 作為示範。
# 使用 get_map() 設定要抓的地點,以及地圖放大的比例。
# location:要抓的地點
# zoom:調整地圖縮放的參數,需要視需求調整
# 在地圖上顯示的文字語言
> map <- get_map(location = 'Canada', zoom = 4, language = "zh-TW")
# 將地圖顯示出來
> ggmap(map)
[顯示結果]
- 看起來沒有很清楚,不過至少可以確定地圖上顯示的是北美洲地區。
2. 再精確一點的地區
整個北美洲太大了,我想要針對指定的地區(城市)進行顯示,在這裡以”溫哥華(Vancouver)”為例。
但是如果直接在location參數上輸入Vancouver(溫哥華),地圖會偏掉。
這時候可以改用經緯度座標來指定:
- 隨意找一個溫哥華內部的地點來定位。
- [範例] 經度:
49.27894861、緯度:-123.11536789
# lon:設定座標,緯度(longitude)、lat:經度(latitude)
> map <- get_map(location = c(lon = -123.11536789, lat = 49.27894861), zoom = 12, language = "zh-TW")
>
> ggmap(map)
[顯示結果]
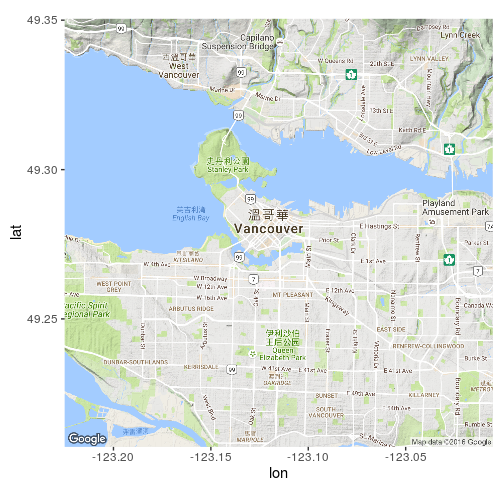
- 嗯,這張看起來清楚多了!
3. 地圖的類型、明暗程度的調整
- 地圖的類型可以用:
maptype參數調整 - 明暗程度可以用:
darken參數調整
詳細的操作在這裡就不多加詳述,可以看看參考資料。
(二) 尋找 OpenData,進行檢視和分類
1. 使用開放資料 Open Data
-
在這裡我使用 Rail occurrence data from January 2004 to present 作為資料來源。(剛好可以對照加拿大的地圖)
-
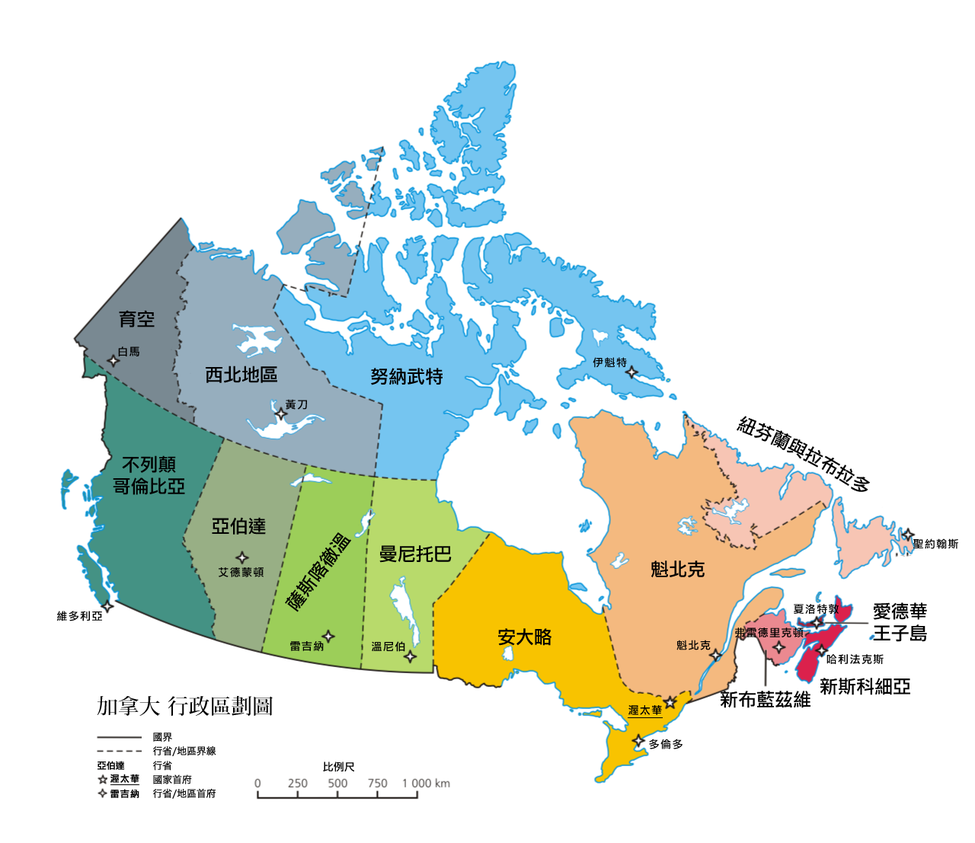
加拿大地圖(省份)
讓我們先下載原始資料檔和說明檔:

2. 檢視資料,取得我們要用的資訊
先看一下欄位名稱:
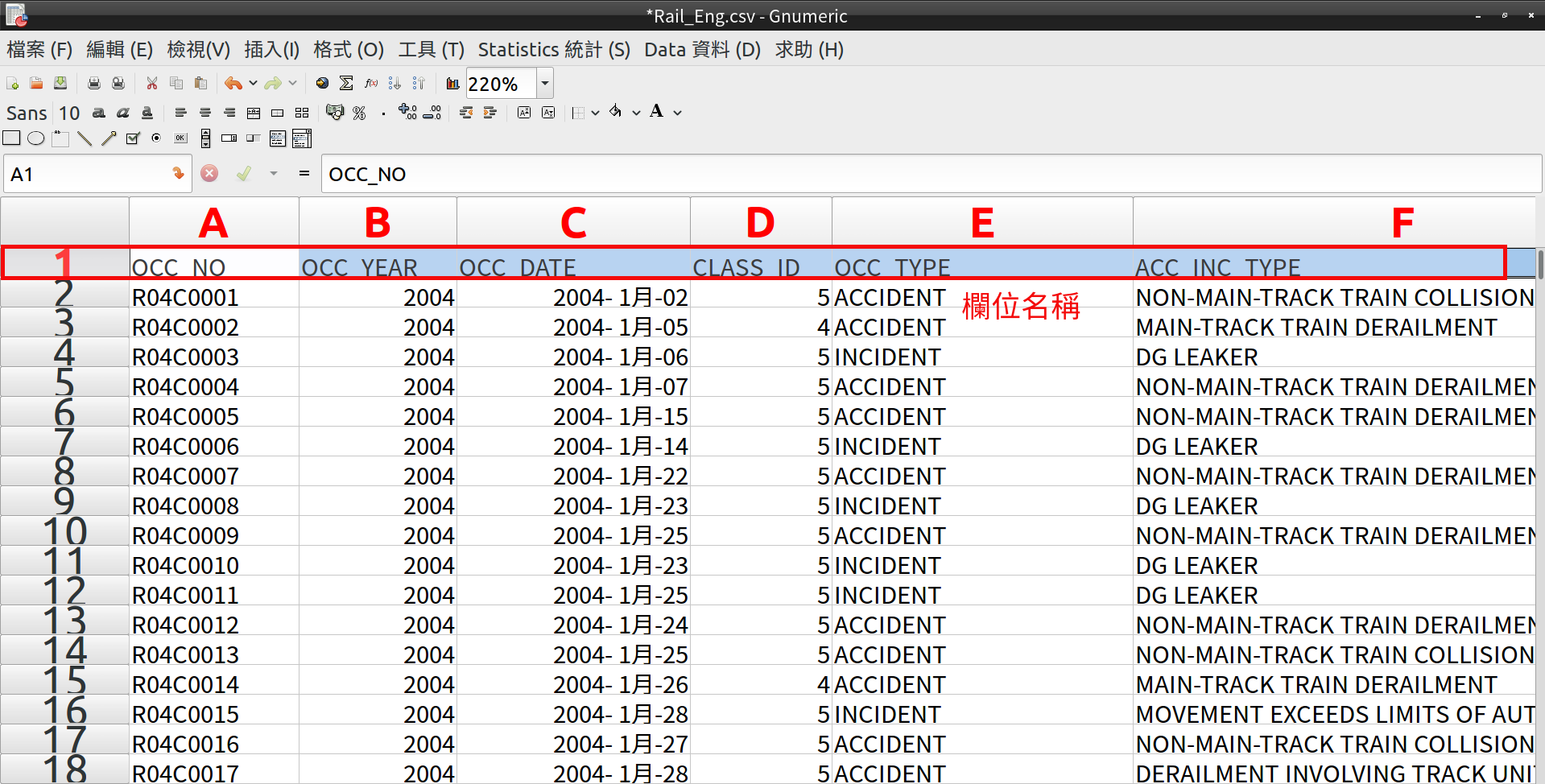
詳細的欄位資訊都在說明檔裡,我們在這裡只需要 OCC_TYPE、ACC_INC_TYPE、PROVINCE(省份) 這三個欄位的資料。
首先要檢查工作目錄的位置是否正確,如果不正確則需要調整:
> getwd()
[1] "/home/shouzo"
>
> setwd("/home/shouzo/r_test") # 切換工作目錄
> getwd()
[1] "/home/shouzo/r_test"
>
>
> dir() # 確認目錄裡的檔案
[1] "dd-20150217.csv" "Rail_Eng.csv"
>
我們試著讀取 Rail_Eng.csv 的檔案內容,你可以看到這個檔案裡的資料有一萬多筆。
> read.csv("Rail_Eng.csv")
# 中間省略...
450 N/A 2016-09-15T09:18:21
451 N/A 2016-09-15T09:18:21
452 N/A 2016-09-15T09:18:21
453 N/A 2016-09-15T09:18:21
454 FLASHING LIGHT SIGNALS AND BELL 2016-09-15T09:18:21
[ reached getOption("max.print") -- omitted 17653 rows ]
因為我們只需要 OCC_TYPE、ACC_INC_TYPE、PROVINCE 這三個欄位的資料,所以要稍微加以細分:
> # 將整個檔案裡的資料檔存入變數 "Ori_Data"
> Ori_Data <- read.csv("Rail_Eng.csv")
>
> # 取得並存放 "OCC_TYPE" 欄位的資料
> OCC_TYPE <- Ori_Data$OCC_TYPE
>
> # 取得並存放 "ACC_INC_TYPE" 欄位的資料
> ACC_INC_TYPE <- Ori_Data$ACC_INC_TYPE
>
> # 取得並存放 "PROVINCE" 欄位的資料
> PROVINCE <- Ori_Data$PROVINCE
剛剛我們分別對 OCC_TYPE、ACC_INC_TYPE、PROVINCE 進行資料的存放和處理,現在我們來看看裡面有哪些內容。
- 查看
OCC_TYPE:
> # 查看 OCC_TYPE 裡面有哪些資料類型
> levels(OCC_TYPE)
[1] "ACCIDENT" "INCIDENT"
>
- 查看
ACC_INC_TYPE:
> # 查看 ACC_INC_TYPE 裡面有哪些資料類型
> levels(ACC_INC_TYPE)
[1] ""
[2] "COLLISION INVOLVING TRACK UNIT"
[3] "CREW MEMBER INCAPACITATED"
[4] "CROSSING"
[5] "DERAILMENT INVOLVING TRACK UNIT"
[6] "DG LEAKER"
[7] "EMPLOYEE"
[8] "FIRE"
[9] "MAIN-TRACK SWITCH IN ABNORMAL POSITION"
[10] "MAIN-TRACK TRAIN COLLISION"
[11] "MAIN-TRACK TRAIN DERAILMENT"
[12] "MOVEMENT EXCEEDS LIMITS OF AUTHORITY"
[13] "NON-MAIN-TRACK TRAIN COLLISION"
[14] "NON-MAIN-TRACK TRAIN DERAILMENT"
[15] "PASSENGER"
[16] "R/S COLL. WITH ABANDONED VEHICLE"
[17] "R/S COLL. WITH OBJECT"
[18] "R/S DAMAGE WITHOUT DERAIL./COLL."
[19] "RUNAWAY ROLLING STOCK"
[20] "SIGNAL LESS RESTRICTIVE THAN REQUIRED"
[21] "TRESPASSER"
[22] "UNPROTECTED OVERLAP OF AUTHORITIES"
>
- 查看
PROVINCE:
> # 查看 PROVINCE 裡面有哪些資料類型
> levels(PROVINCE)
[1] "" "ALBERTA" "BRITISH COLUMBIA"
[4] "MANITOBA" "NEW BRUNSWICK" "NEWFOUNDLAND"
[7] "NORTHWEST TERRITORIES" "NOVA SCOTIA" "ONTARIO"
[10] "QU\xc9BEC" "SASKATCHEWAN"
>
3. 先想一下︰我們用這些資料要做什麼?
這份是源自於加拿大的 OpenData 資料,而我現在想要用這些資料去 觀察 各省份地鐵事故分佈的情形,可以怎麼做?
這個問題可以從幾個觀點來看(由簡單到複雜):
- 哪一個地區比較常發生事故?
- 哪一個地區比較常發生”何種類型”的事故?
- …其他的之後可以再想想
這一次先探討上方的第1點,我個人的想法如下: 『 根據事故發生的次數,以 “點狀圖” 的方式去凸顯發生頻率。』
- 點越大,就代表事故發生的次數越多。
就像是這張圖:

(三) 將分類後的資料放在地圖上,進行視覺化
我們從 PROVINCE 這個欄位中知道資料分別來自 9 個省份 (扣除兩項無法辨別的資料);讓我們先個別幫這些地區定義座標,這樣在之後便可以精準的定位:
- 只要在各省份中隨意找一個地點設為座標即可,詳情請見 搜尋和取得座標
- ALBERTA
- 座標:(56.245426, -115.134777)
- BRITISH COLUMBIA
- 座標:(54.156673, -124.801499)
- MANITOBA
- 座標:(55.829413, -97.121341)
- NEW BRUNSWICK
- 座標:(46.717936, -66.294149)
- NEWFOUNDLAND
- 座標:(54.501215, -61.985263)
- NORTHWEST TERRITORIES
- 座標:(64.585305, -121.295028)
- NOVA SCOTIA
- 座標:(45.108690, -63.650974)
- ONTARIO
- 座標:(51.222450, -85.156691)
- SASKATCHEWAN
- 座標:(54.829432, -105.995397)
接著,讓我們看看這些地區在資料中出現的次數:
> summary(PROVINCE)
ALBERTA BRITISH COLUMBIA
1 3758 3082
MANITOBA NEW BRUNSWICK NEWFOUNDLAND
1711 324 69
NORTHWEST TERRITORIES NOVA SCOTIA ONTARIO
19 152 4819
QU\xc9BEC SASKATCHEWAN
2399 1773
>