R 語言資料分析實務 (2)
資料科學 Data Science 系列
文字探勘 - 文字雲製作
姓名:羅左欣
日期:2016/10/17(一)
本著作係採用創用 CC 姓名標示-非商業性-相同方式分享 3.0 台灣 授權條款授權.

Agenda
(一) Prepare:預備工作
(二) Basic:基本介紹與操作
(三) Theme:文字雲製作
(四) Reference:學習資源
(一) Prepare:
預備工作
(一) Prepare:預備工作
(一) Prepare:預備工作

在這個系列的簡報中,主要以 "RStudio" 做為主要軟體。
(二) Basic:基本介紹與操作
(二) Basic:
基本介紹與操作
(二) Basic:基本介紹與操作
1. 網頁分析
1. 網頁分析
教材網址:
(二) Basic:基本介紹與操作
1. 網頁分析
尋找 Xpath
(二) Basic:基本介紹與操作
Google 瀏覽器 (Chrome) - 開發人員工具
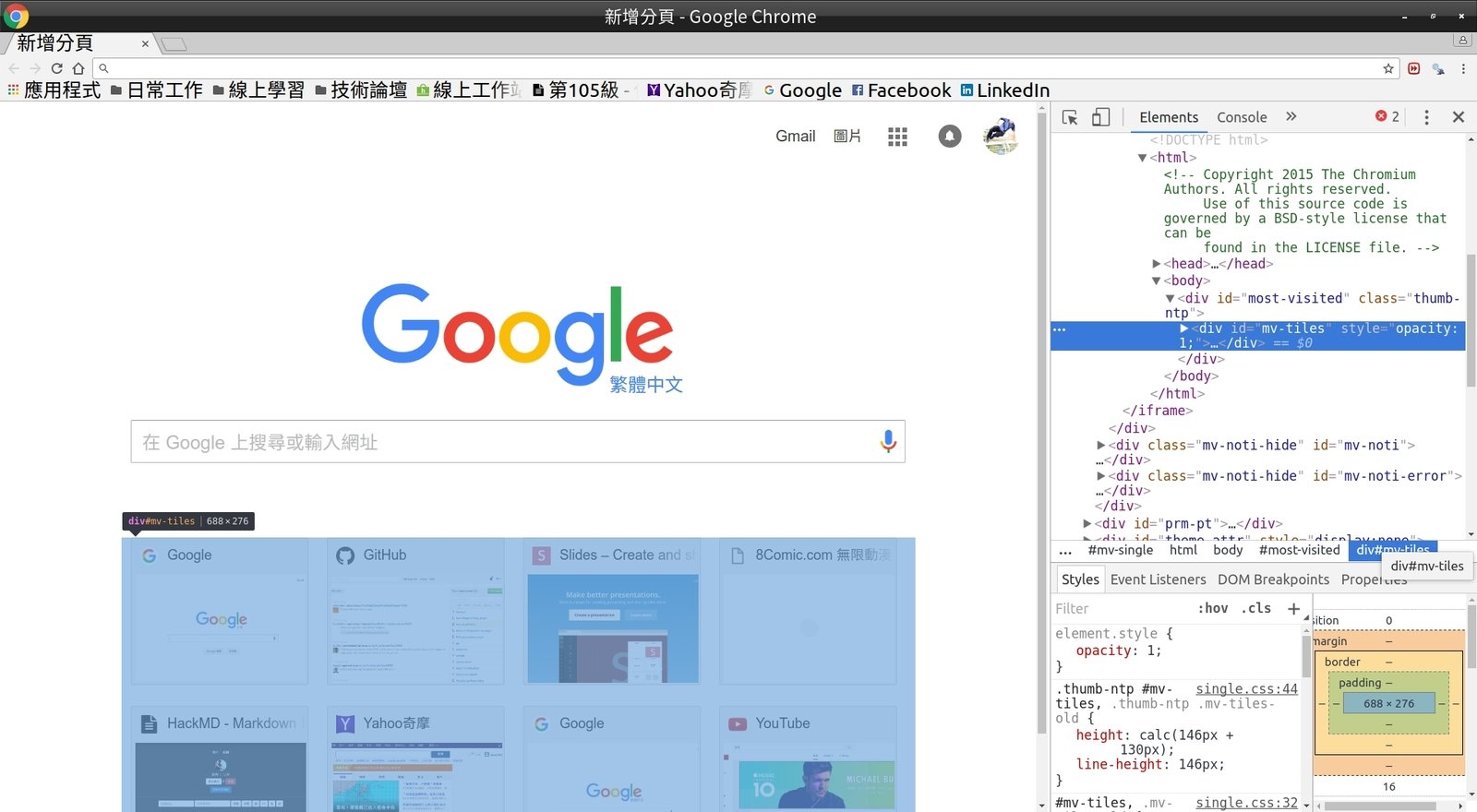
1. 網頁分析
(二) Basic:基本介紹與操作
Mozilla Firefox 瀏覽器 - 擴充套件 FireBug
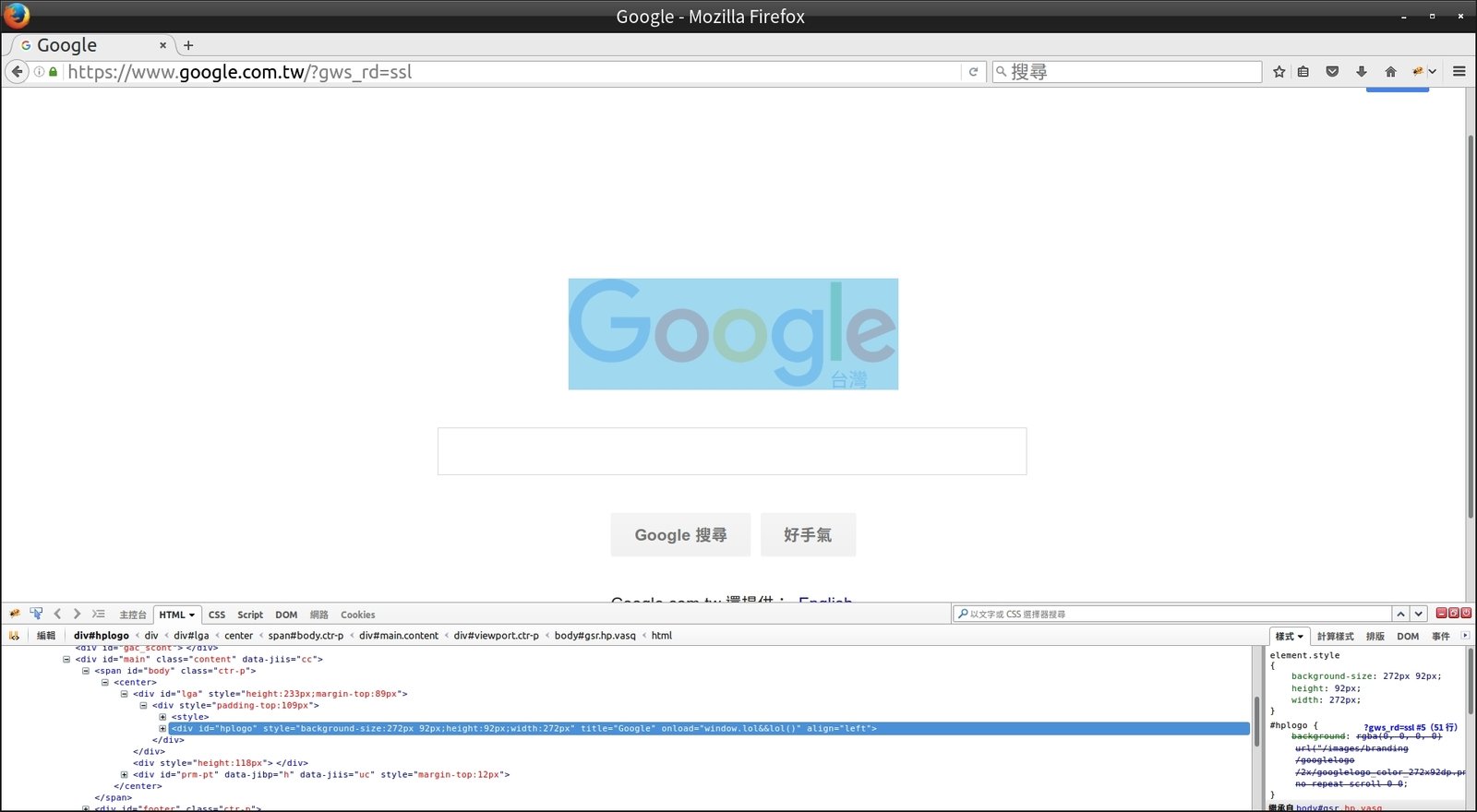
1. 網頁分析
(二) Basic:基本介紹與操作
1. 網頁分析
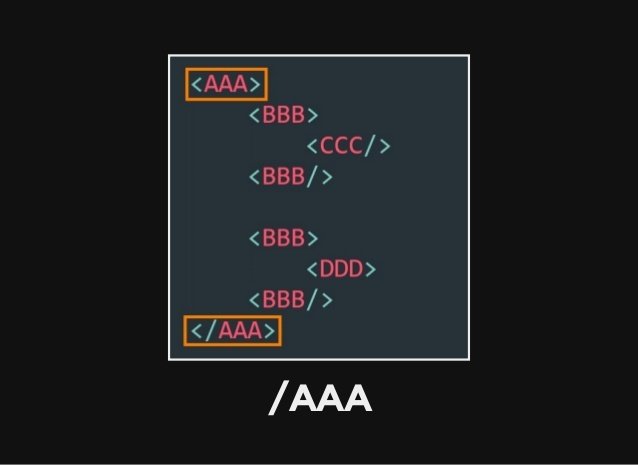
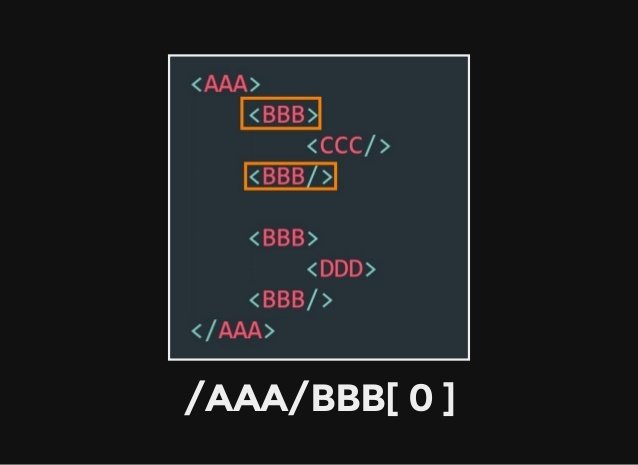
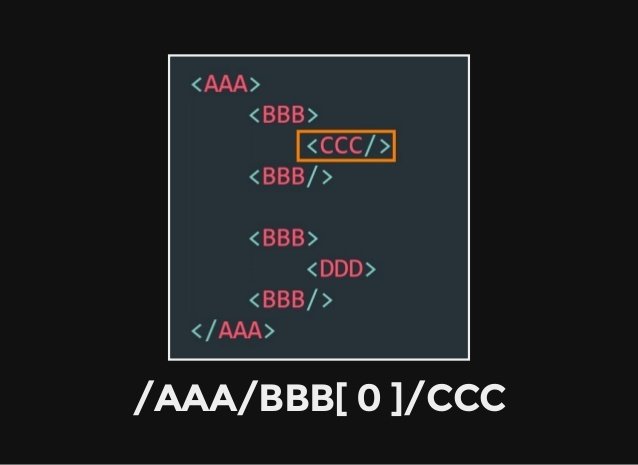
Xpath 概觀
註:本篇內容引用自
(二) Basic:基本介紹與操作
1. 網頁分析
(二) Basic:基本介紹與操作
1. 網頁分析
(二) Basic:基本介紹與操作
1. 網頁分析
(二) Basic:基本介紹與操作
1. 網頁分析
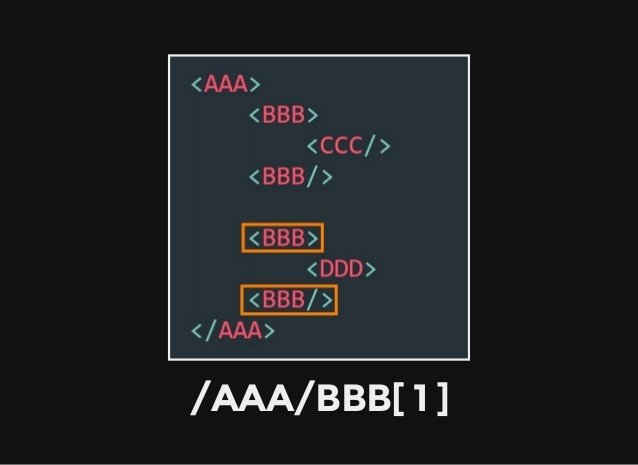
(二) Basic:基本介紹與操作
1. 網頁分析
尋找特定物件的 Xpath
(二) Basic:基本介紹與操作
1. 網頁分析

(二) Basic:基本介紹與操作
1. 網頁分析
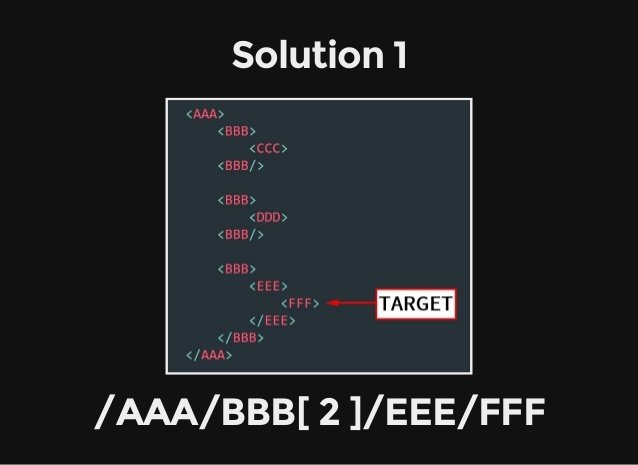
(二) Basic:基本介紹與操作
1. 網頁分析

(二) Basic:基本介紹與操作
1. 網頁分析
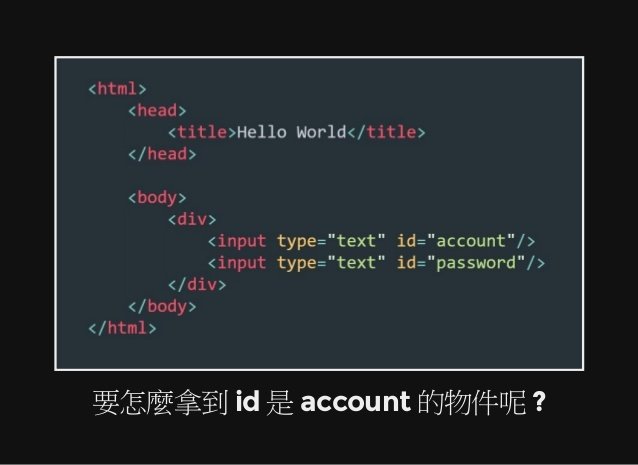
透過 TAG 屬性尋找特定物件
(二) Basic:基本介紹與操作
1. 網頁分析
(二) Basic:基本介紹與操作
1. 網頁分析
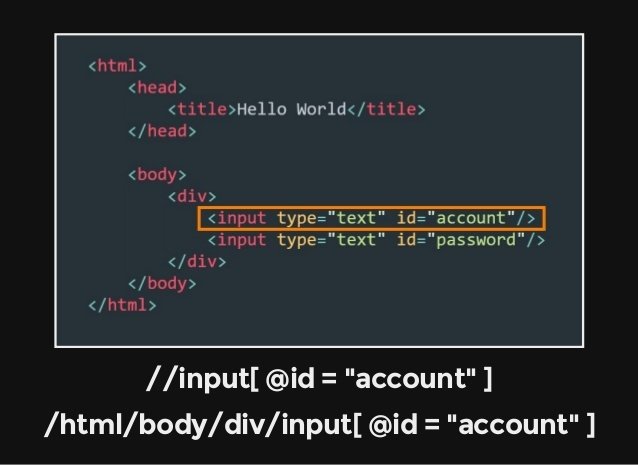
(二) Basic:基本介紹與操作
2. 資料的讀取
2. 資料的讀取
(二) Basic:基本介紹與操作
2. 資料的讀取
常見的資料格式:
(1) CSV
(2) XML
(3) JSON
(4) DB (資料庫)
(5) RData
(6) SPSS、Stata、SAS、Octave ...
介紹如何讀取 CSV 檔
(二) Basic:基本介紹與操作
讀取CSV:
STEP1:使用read.table()
# 讀取檔案的完整路徑(在此為網路位址)
theUrl <- "http://www.jaredlander.com/data/Tomato%20First.csv"
# 將檔案載入R,在這裡設定
tomato <- read.table (file = theUrl, header = TRUE, sep = ",")
2. 資料的讀取
(二) Basic:基本介紹與操作
讀取CSV:
STEP2:使用head()
STEP3:使用data.frame()
2. 資料的讀取
(二) Basic:基本介紹與操作
STEP2、STEP3:執行結果
> head(tomato) # 查看資料表的第一部分
Round Tomato Price Source Sweet Acid Color Texture Overall
1 1 Simpson SM 3.99 Whole Foods 2.8 2.8 3.7 3.4 3.4
2 1 Tuttorosso (blue) 2.99 Pioneer 3.3 2.8 3.4 3.0 2.9
3 1 Tuttorosso (green) 0.99 Pioneer 2.8 2.6 3.3 2.8 2.9
4 1 La Fede SM DOP 3.99 Shop Rite 2.6 2.8 3.0 2.3 2.8
5 2 Cento SM DOP 5.49 D Agostino 3.3 3.1 2.9 2.8 3.1
6 2 Cento Organic 4.99 D Agostino 3.2 2.9 2.9 3.1 2.9
Avg.of.Totals Total.of.Avg
1 16.1 16.1
2 15.3 15.3
3 14.3 14.3
4 13.4 13.4
5 14.4 15.2
6 15.5 15.1
>
> x <- 10:1
> y <- -4:5
> # "q"是一個 character 型態的向量
> q <- c("Hockey", "Football", "Baseball", "Curling", "Rugby", "Lacrosse", "Basketball", "Tennis", "Cricket", "Soccer")
>
> theDF <- data.frame(First = x, Second = y, Sport = q, stringsAsFactors = FALSE)
> theDF$Sport
[1] "Hockey" "Football" "Baseball" "Curling" "Rugby" "Lacrosse"
[7] "Basketball" "Tennis" "Cricket" "Soccer" 2. 資料的讀取
(三) Theme:
文字雲製作
(三) Theme:文字雲製作
(三) Theme:文字雲製作
(1) 是"文字探勘"上常用的呈現手法之一
(2) 出現頻率越高的字詞,會加以突顯出來
(3) 比起表格類型的結果,文字雲更美觀
(三) Theme:文字雲製作
1. 處理英文資料
1. 處理英文資料
(三) Theme:文字雲製作
1. 處理英文資料
STEP 1:準備要分析的資料
STEP 2:安裝和載入所需的套件
STEP 3:進行"文字探勘"
STEP 4:製作"字詞矩陣"
STEP 5:產生"文字雲"
處理步驟:
教材網址:
(三) Theme:文字雲製作
1. 處理英文資料
STEP 1:準備要分析的資料
網址:

Big Data and Analytics: Creating New Value
(三) Theme:文字雲製作
1. 處理英文資料
STEP 1:準備要分析的資料
紅線圈選區域為本次欲分析之內容

(三) Theme:文字雲製作
1. 處理英文資料
STEP 2:安裝和載入所需的套件
# 安裝套件
install.packages("rvest") # "網頁分析"用
install.packages("tm") # "文字探勘"用
install.packages("SnowballC") # Text stemming
install.packages("wordcloud") # 產生"文字雲"用
install.packages("RColorBrewer") # Color palettes
# 載入套件
library("rvest")
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")開啟 RStudio,在命令列中輸入以下指令:
(三) Theme:文字雲製作
1. 處理英文資料
STEP 3:進行"文字探勘"
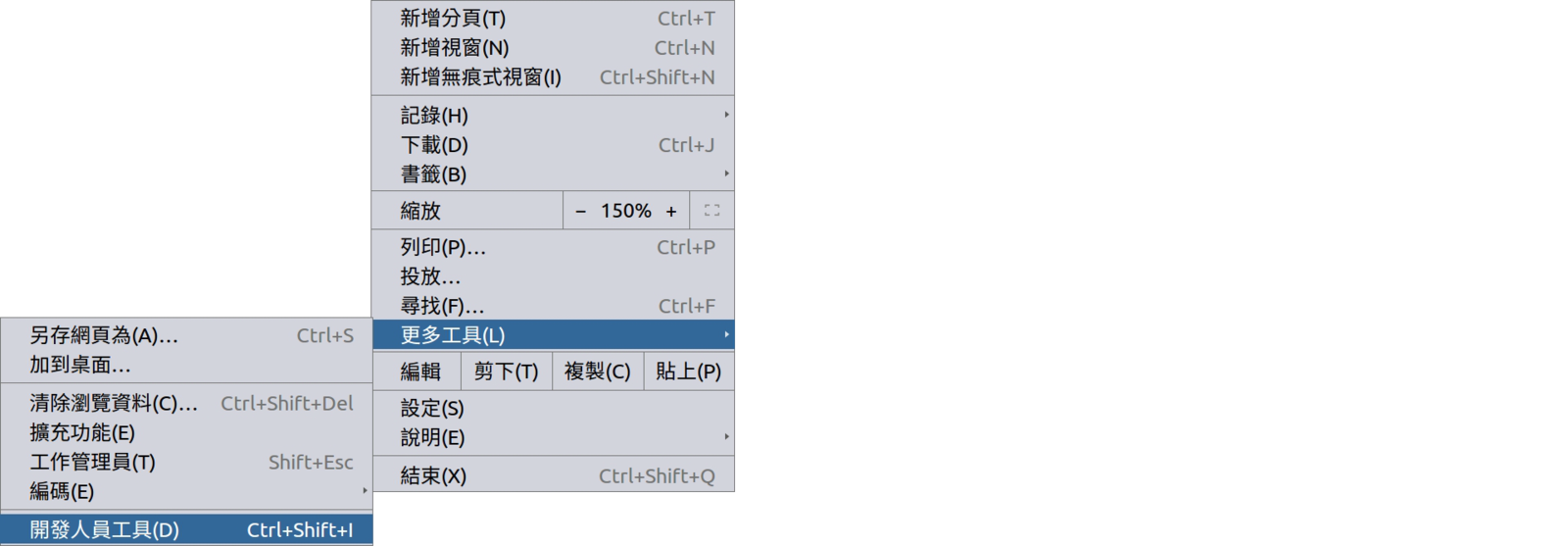
在 Chrome 點選"開發人員工具" (亦可按下 "F12"鍵)

(三) Theme:文字雲製作
1. 處理英文資料
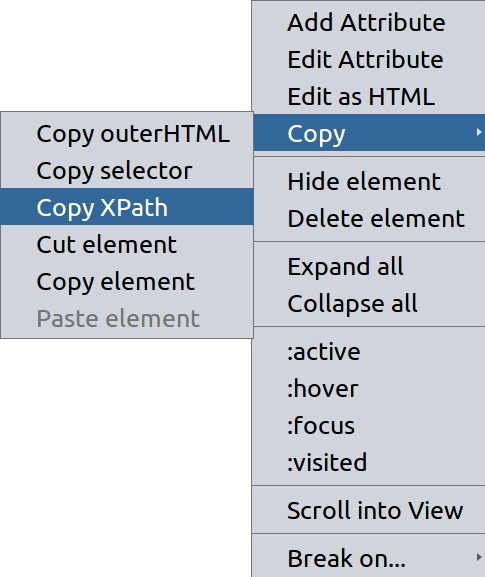
利用選取工具找到段落後,在對應節點按右鍵
圈選文章後,點選 "Copy Xpath"
2
2


1
STEP 3:進行"文字探勘"
(三) Theme:文字雲製作
1. 處理英文資料
STEP 3:進行"文字探勘"
將取得的 Xpath 貼在記事本上 (稍後會用到)
//*[@id="story-body"]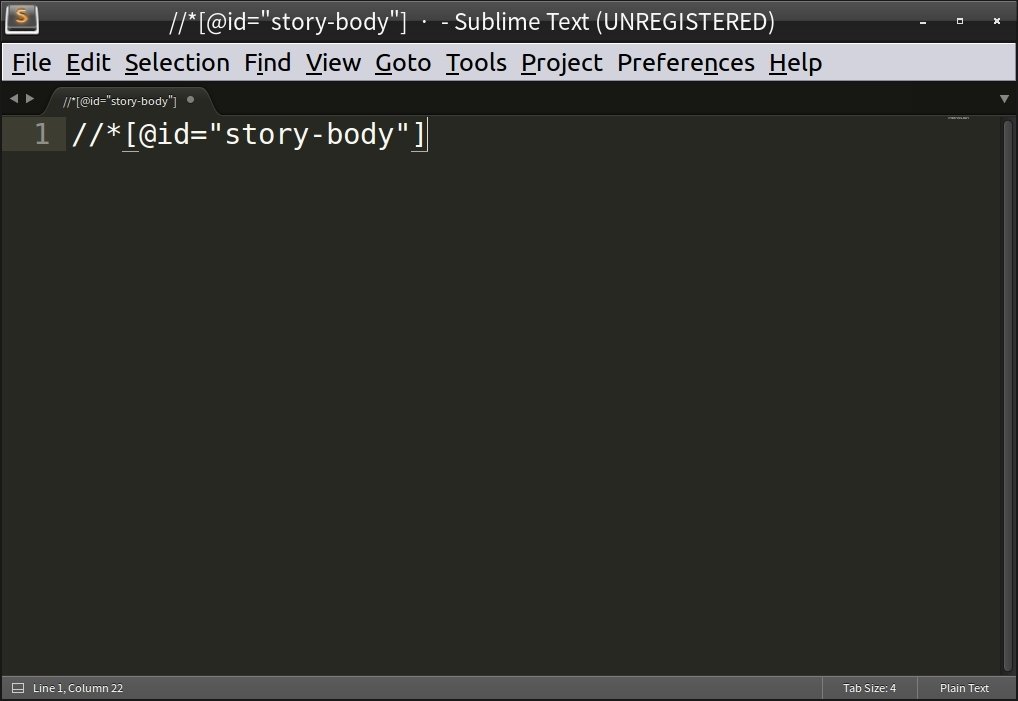
文章的 Xpath:
任何一個可以貼上文字的地方
(三) Theme:文字雲製作
1. 處理英文資料
STEP 3:進行"文字探勘"
# 擷取網頁內容,將網頁下載後存入"source.page"物件
source.page <- read_html("http://www.technewsworld.com/story/83998.html")
# 利用 Xpath 取得文章內容
source.content <- html_nodes(source.page, xpath = '//*[@id="story-body"]')
# 取得 HTML 中的文字資料
content <- html_text(source.content)
# 顯示資料 (此時文章仍包含多餘字元)
content在命令列中輸入以下指令:

(三) Theme:文字雲製作
1. 處理英文資料
STEP 3:進行"文字探勘"
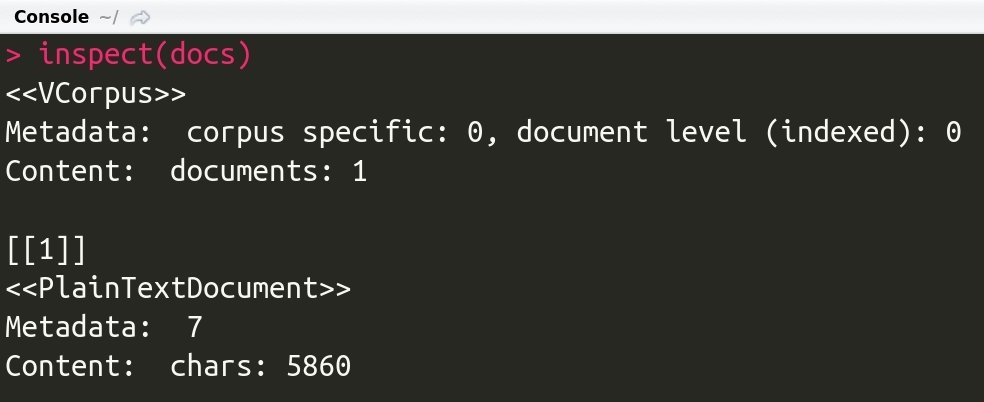
# 將內容以"語料庫"的形式儲存
docs <- Corpus(VectorSource(content))
# 檢查內容
inspect(docs)在命令列中輸入以下指令:
(三) Theme:文字雲製作
1. 處理英文資料
STEP 3:進行"文字探勘"
過濾特殊字元:在命令列中輸入以下指令,將特殊字元以"空白"取代
過濾贅詞、符號:在命令列中輸入以下指令,移除贅詞和多餘的符號
# 將特殊的字元以"空白"取代
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
docs <- tm_map(docs, toSpace, "/") # 將"/"以"空白"取代
docs <- tm_map(docs, toSpace, "@") # 將"@"以"空白"取代
docs <- tm_map(docs, toSpace, "\\|") # 將"\\|"以"空白"取代# Convert the text to lower case
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeNumbers) # 移除數字
# 移除常見的"轉折詞彙"
docs <- tm_map(docs, removeWords, stopwords("english"))
docs <- tm_map(docs, removePunctuation) # 移除標點符號
docs <- tm_map(docs, stripWhitespace) # 移除額外的"空白"(三) Theme:文字雲製作
1. 處理英文資料
STEP 4:製作"字詞矩陣"
dtm <- TermDocumentMatrix(docs)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing = TRUE)
d <- data.frame(word = names(v),freq = v)
# 顯示前10個出現頻率最高的字詞
head(d, 10)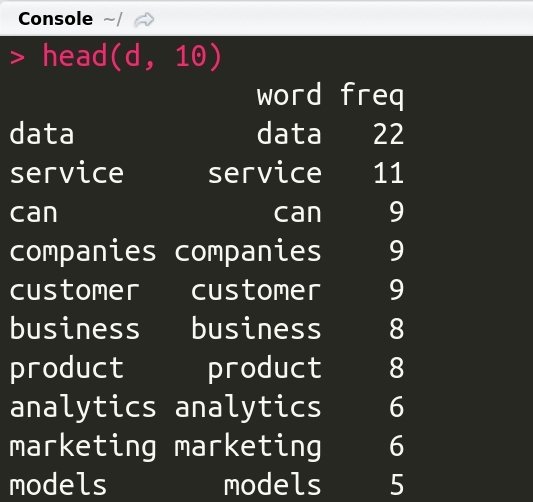
在命令列中輸入以下指令:
(三) Theme:文字雲製作
1. 處理英文資料
STEP 5:產生"文字雲"
在命令列中輸入以下指令:
# 設定可重複的亂數序列
set.seed(1000)
# 製作文字雲
wordcloud(words = d$word, freq = d$freq, min.freq = 2,
max.words = 30, random.order = FALSE, rot.per = 0.35,
colors = brewer.pal(8, "Dark2"))
(三) Theme:文字雲製作
2. 處理中文資料
2. 處理中文資料
(三) Theme:文字雲製作
2. 處理中文資料
STEP 1:準備要分析的資料
STEP 2:安裝和載入所需的套件
STEP 3:進行"文字探勘"
STEP 4:製作"字詞矩陣"
STEP 5:產生"文字雲"
處理步驟:
參考教材:文字資料探勘實作
教材網址:
(三) Theme:文字雲製作
2. 處理中文資料
STEP 1:準備要分析的資料
【雙颱片】海馬下午增強中颱 不排除升級強颱
網址:
(三) Theme:文字雲製作
2. 處理中文資料
STEP 1:準備要分析的資料
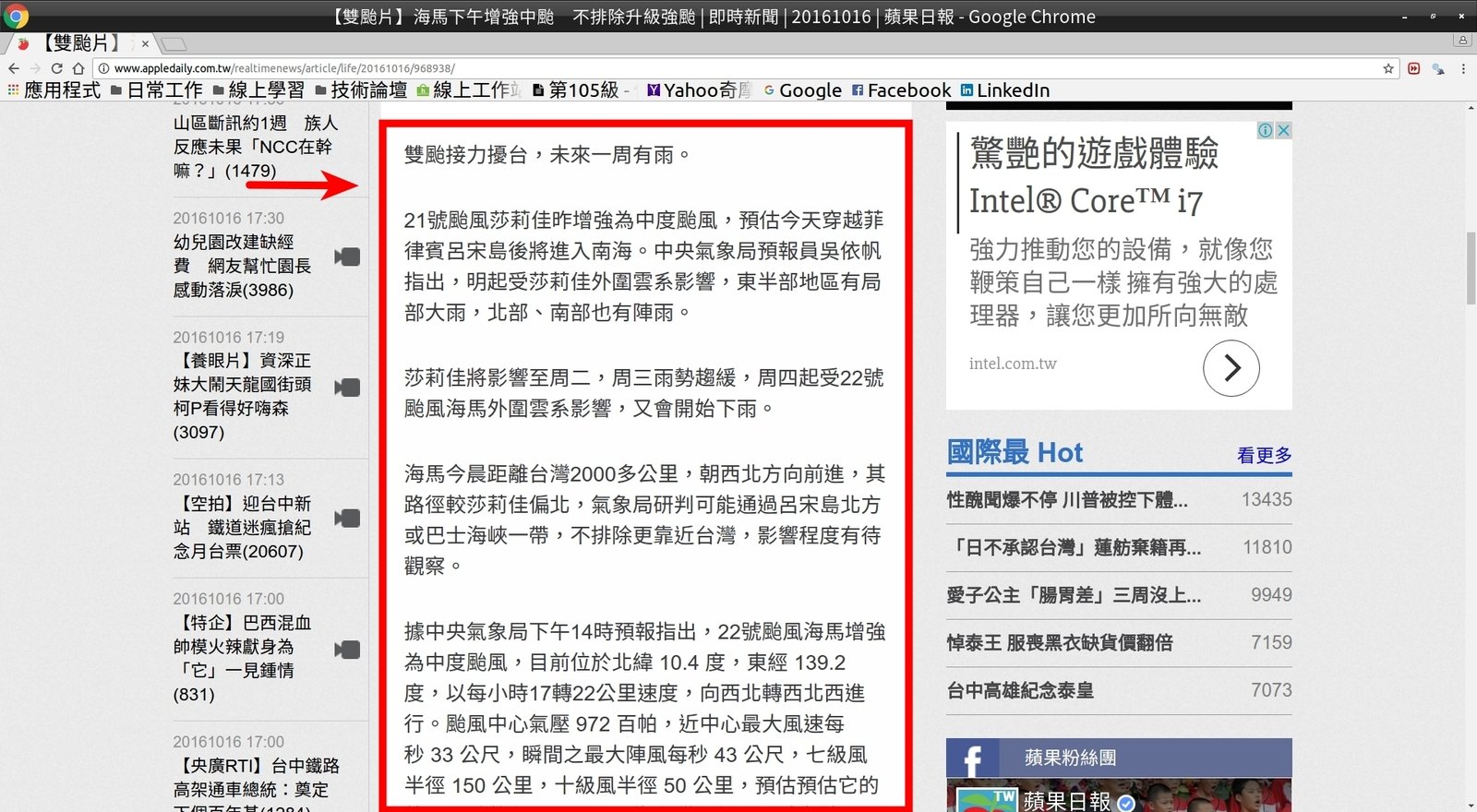
紅線圈選區域為本次欲分析之內容
(三) Theme:文字雲製作
2. 處理中文資料
STEP 2:安裝和載入所需的套件
開啟 RStudio,在命令列中輸入以下指令:
# 安裝套件
install.packages("rvest") # "網頁分析"用
install.packages("jiebaR") # "中文斷詞"用
install.packages("tm") # "文字探勘"用
install.packages("wordcloud2") # 產生"文字雲"用
# 載入套件
library("rvest")
library("jiebaR")
library("tm")
library("wordcloud2")(三) Theme:文字雲製作
2. 處理中文資料
STEP 3:進行"文字探勘"
在 Chrome 點選"開發人員工具" (亦可按下 "F12"鍵)
(三) Theme:文字雲製作
2. 處理中文資料
STEP 3:進行"文字探勘"
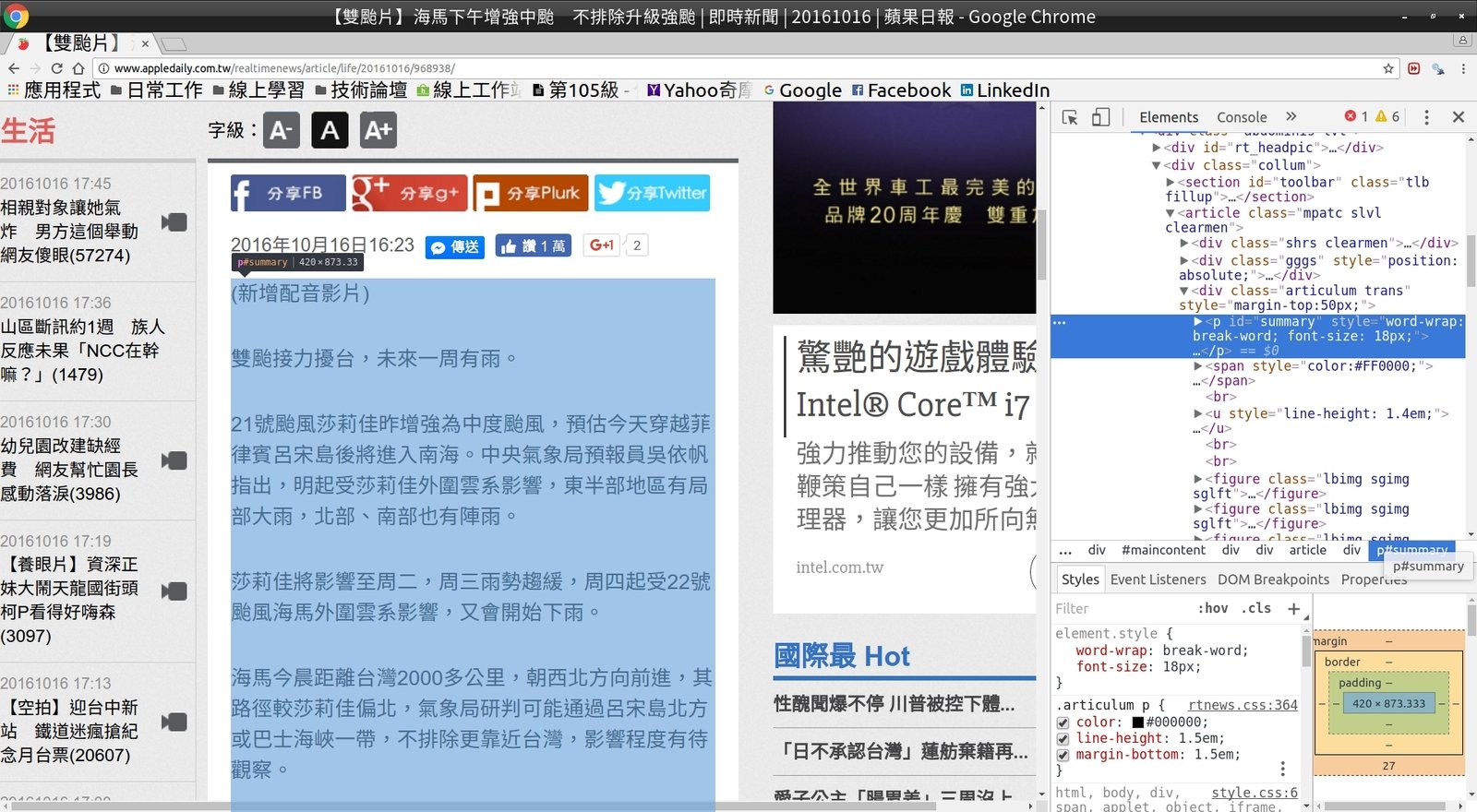
利用選取工具找到段落後,在對應節點按右鍵
1
2
圈選文章後,點選 "Copy Xpath"
(三) Theme:文字雲製作
2. 處理中文資料
STEP 3:進行"文字探勘"
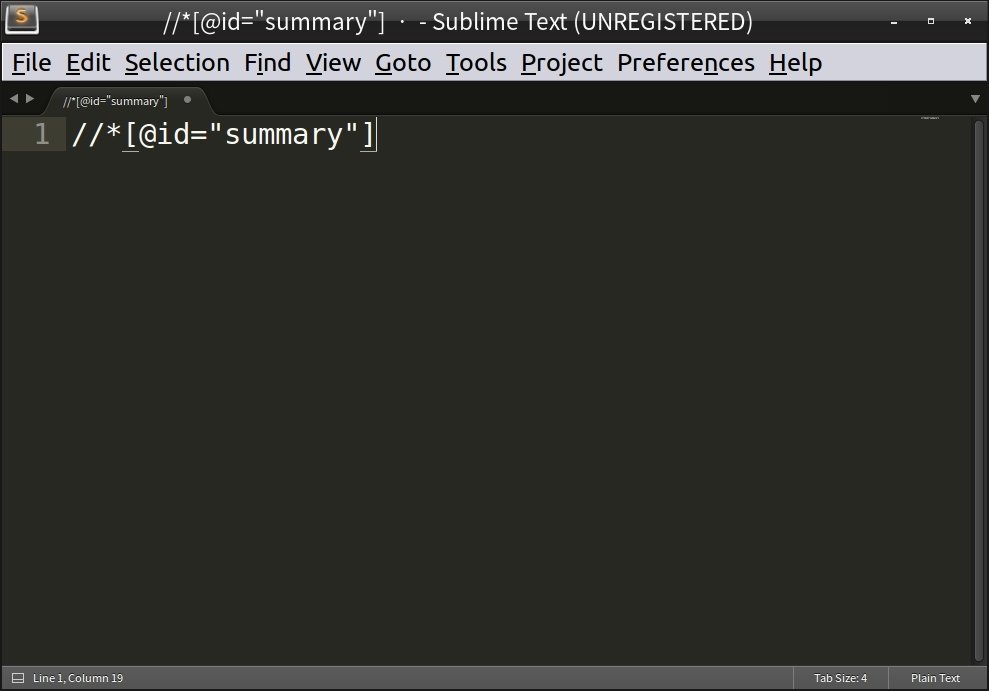
將取得的 Xpath 貼在記事本上 (稍後會用到)
//*[@id="summary"]文章的 Xpath:
任何一個可以貼上文字的地方
(三) Theme:文字雲製作
2. 處理中文資料
STEP 3:進行"文字探勘"
# 擷取網頁內容,將網頁下載後存入"source.page"物件
source.page <- read_html("http://www.appledaily.com.tw/realtimenews/article/life/20161016/968938/")
# 利用 Xpath 取得文章內容
source.content <- html_nodes(source.page, xpath = '//*[@id="summary"]')
# 取得 HTML 中的文字資料
content <- html_text(source.content)
# 顯示資料 (此時文章仍包含多餘字元)
content
# 啟用 jiebaR 套件裡的斷詞引擎
mixseg = worker()
content.vec <- segment(code = content, jiebar = mixseg)
在命令列中輸入以下指令:

(三) Theme:文字雲製作
2. 處理中文資料
STEP 3:進行"文字探勘"
在命令列中輸入以下指令:
space_tokenizer = function(x){
unlist(strsplit(as.character(x[[1]]), '[[:space:]]+'))
}
jieba_tokenizer = function(d){
unlist(segment(d[[1]], mixseg))
}
# 撰寫 CNCorpus 副程式
#### CNCorpus Function Start ####
CNCorpus = function(d.vec){
doc <- VCorpus(VectorSource(d.vec))
doc <- unlist(tm_map(doc ,jieba_tokenizer), recursive = F)
doc <- lapply(doc ,function(d)paste(d, collapse = ' '))
Corpus(VectorSource(doc))
}
#### CNCorpus Function END ####CNCorpus 副程式:將內容以"語料庫"的形式儲存
(三) Theme:文字雲製作
2. 處理中文資料
在命令列中輸入以下指令:
content.corpus = CNCorpus(list(content.vec)) # 執行 CNCorpus 副程式
content.corpus <- tm_map(content.corpus, removeNumbers) # 移除數字
control.list = list(wordLengths = c(2, Inf),tokenize = space_tokenizer)
content.dtm <- DocumentTermMatrix(content.corpus, control = control.list)
inspect(content.dtm) # 檢查內容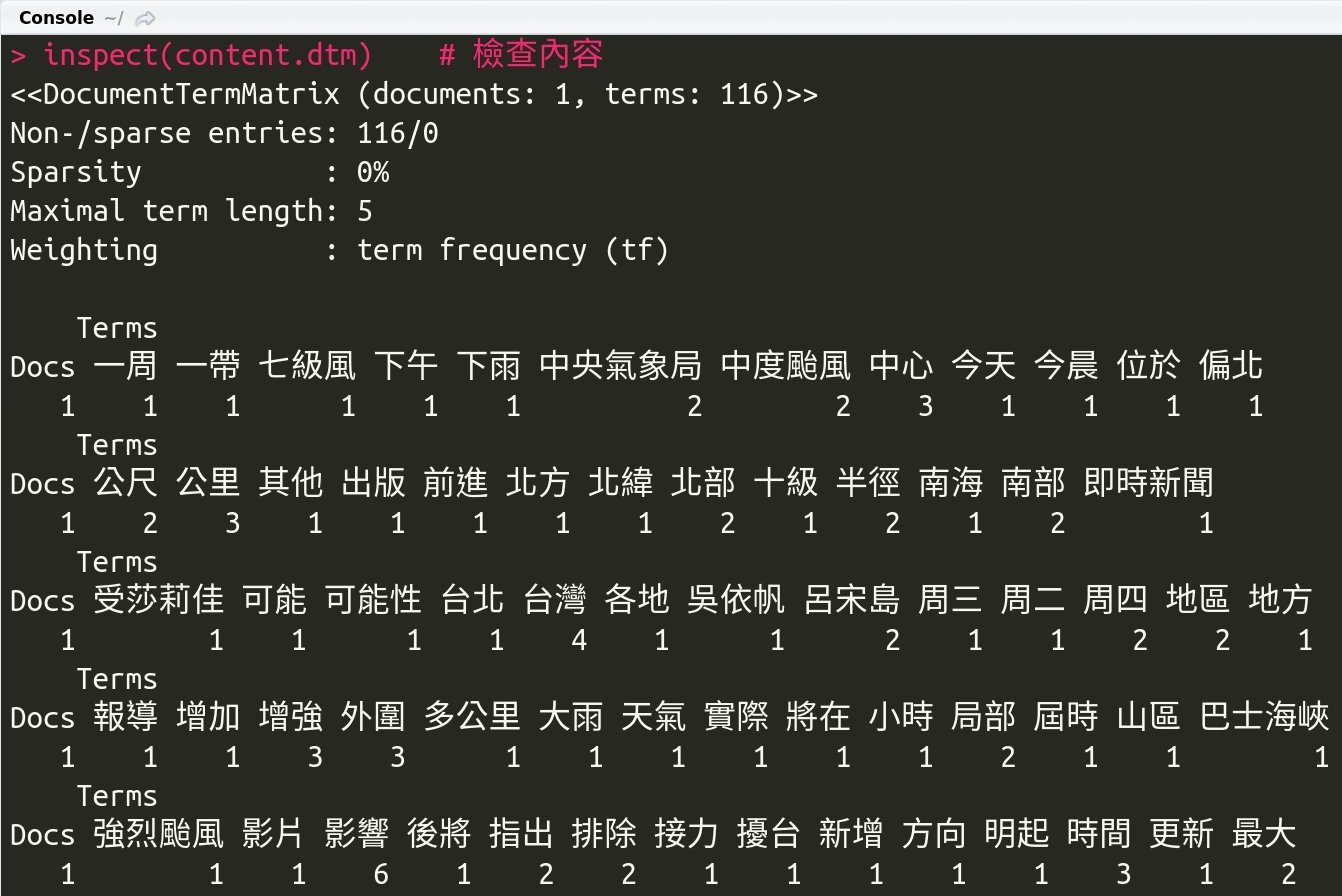
STEP 4:製作"字詞矩陣"
(三) Theme:文字雲製作
2. 處理中文資料
在命令列中輸入以下指令:
frequency <- colSums(as.matrix(content.dtm))
frequency <- sort(frequency, decreasing = TRUE)[1:100]
wordcloud2(as.table(frequency), fontFamily = '微软雅黑', shape = 'star')
STEP 5:產生"文字雲"
(四) Reference:
學習資源
(四) Reference:學習資源
(四) Reference:學習資源
1. R 語言翻轉教室 - Wush Wu、Chih Cheng Liang、Johnson Hsieh
一、中文教材
2. 手把手教你 R 語言資料分析實務 - 張毓倫&陳柏亨
3. R 軟體與資料探勘之開發與應用 - 陳志華
二、英文教材
1. DataCamp
線上教材
2. R for Data Science

推薦書籍
R 軟體資料分析基礎與應用

作者: Jared P. Lander
譯者:鍾振蔚
出版社:旗標
(四) Reference:學習資源
相關社群

Taiwan R User Group
台灣資料科學年會

資料視覺化 / Data Visualization

(四) Reference:學習資源