資料探勘 Data Mining (3)
簡易視覺化
資料科學 Data Science 系列 (3) - 資料探勘 (3)
姓名:羅左欣
日期:2016/6/6(一)
本著作係採用創用 CC 姓名標示-非商業性-相同方式分享 3.0 台灣 授權條款授權.

目錄 Contents
- 前情回顧:資料的讀取
- 主題:簡易視覺化
- 學習資源
資料科學 Data Science 系列 (3) - 資料探勘 (3)
1. 前情回顧
資料的讀取
資料科學 Data Science 系列 (3) - 資料探勘 (3)
1. 前情回顧:資料的讀取
(1) CSV檔
常見的資料有以下格式:
由於篇幅的關係,本章只介紹該如何 讀取CSV檔 。
(2) EXCEL檔
(3) 資料庫
(4) 其他格式...
STEP1:使用read.table()
> # 讀取檔案的完整路徑(在此為網路位址)
> theUrl <- "http://www.jaredlander.com/data/Tomato%20First.csv"
>
> # 將檔案載入R,在這裡設定
> tomato <- read.table (file = theUrl, header = TRUE, sep = ",")
> 1. 前情回顧:資料的讀取
STEP2:使用head()
STEP3:使用data.frame()
1. 前情回顧:資料的讀取
STEP2、STEP3:執行結果
> head(tomato) # 查看資料表的第一部分
Round Tomato Price Source Sweet Acid Color Texture Overall
1 1 Simpson SM 3.99 Whole Foods 2.8 2.8 3.7 3.4 3.4
2 1 Tuttorosso (blue) 2.99 Pioneer 3.3 2.8 3.4 3.0 2.9
3 1 Tuttorosso (green) 0.99 Pioneer 2.8 2.6 3.3 2.8 2.9
4 1 La Fede SM DOP 3.99 Shop Rite 2.6 2.8 3.0 2.3 2.8
5 2 Cento SM DOP 5.49 D Agostino 3.3 3.1 2.9 2.8 3.1
6 2 Cento Organic 4.99 D Agostino 3.2 2.9 2.9 3.1 2.9
Avg.of.Totals Total.of.Avg
1 16.1 16.1
2 15.3 15.3
3 14.3 14.3
4 13.4 13.4
5 14.4 15.2
6 15.5 15.1
>
>
> x <- 10:1
> y <- -4:5
> # "q"是一個 character 型態的向量
> q <- c("Hockey", "Football", "Baseball", "Curling", "Rugby", "Lacrosse", "Basketball", "Tennis", "Cricket", "Soccer")
>
> theDF <- data.frame(First = x, Second = y, Sport = q, stringsAsFactors = FALSE)
> theDF$Sport
[1] "Hockey" "Football" "Baseball" "Curling" "Rugby" "Lacrosse"
[7] "Basketball" "Tennis" "Cricket" "Soccer"
> 1. 前情回顧:資料的讀取
2. 簡易視覺化
資料科學 Data Science 系列 (3) - 資料探勘 (3)
空間資料視覺化
繪製地圖與資料分佈圖
2. 簡易視覺化
本次範例應用之素材如下
2. 簡易視覺化
台灣地圖
使用素材(1)
2. 簡易視覺化
使用素材(2)
2. 簡易視覺化
地圖搭配開放資料,進行視覺化
2. 簡易視覺化
# 安裝套件(如果沒有才需要安裝)
install.packages("ggmap") # 安裝"ggmap"套件
install.packages("mapproj") # 安裝"mapproj"套件
# 載入套件
library(ggmap) # 載入"ggmap"套件
library(mapproj) # 載入"mapproj"套件
# 取得台灣地圖
map <- get_map(location = 'Taiwan', zoom = 7, language = "zh-TW")
# 顯示地圖
ggmap(map)-
必備套件:ggmap、mapproj
STEP1:繪製基本地圖(1)
2. 簡易視覺化
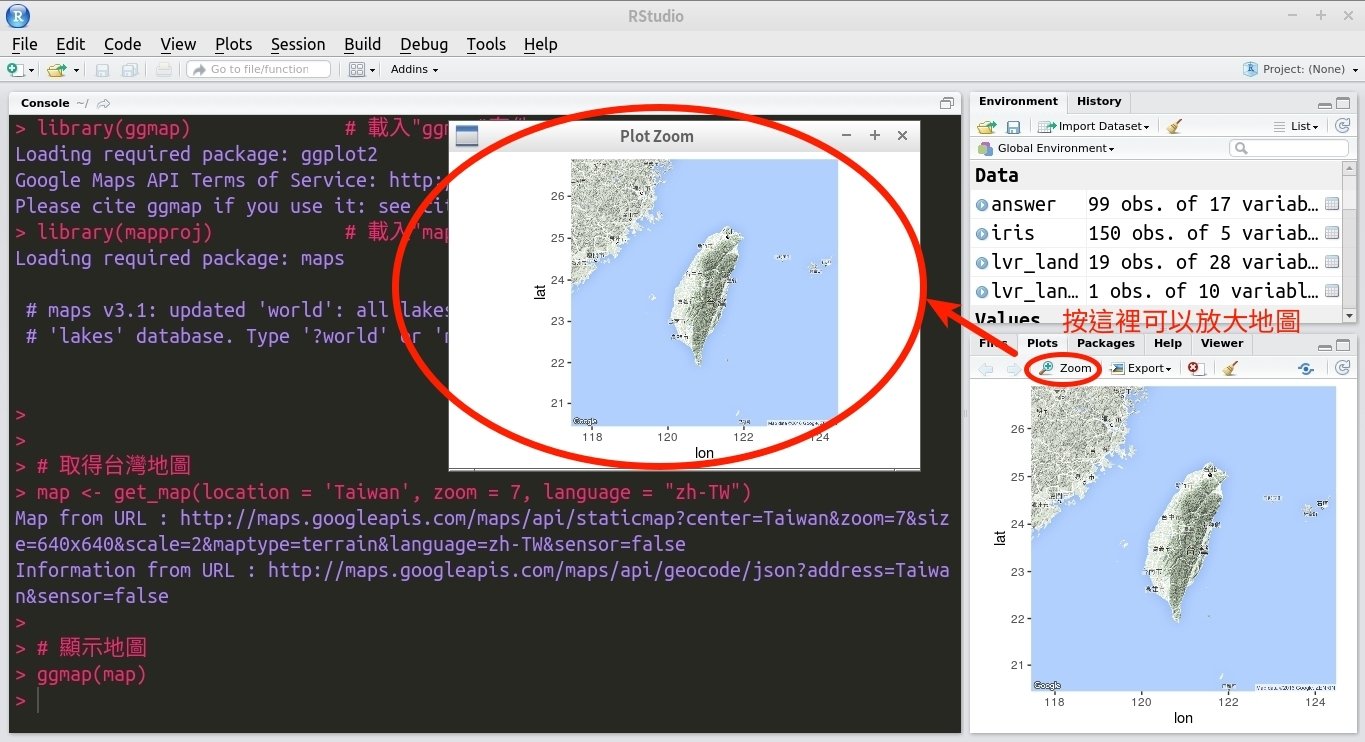
STEP1:繪製基本地圖 (執行結果)
2. 簡易視覺化
STEP2:取得資料(1)
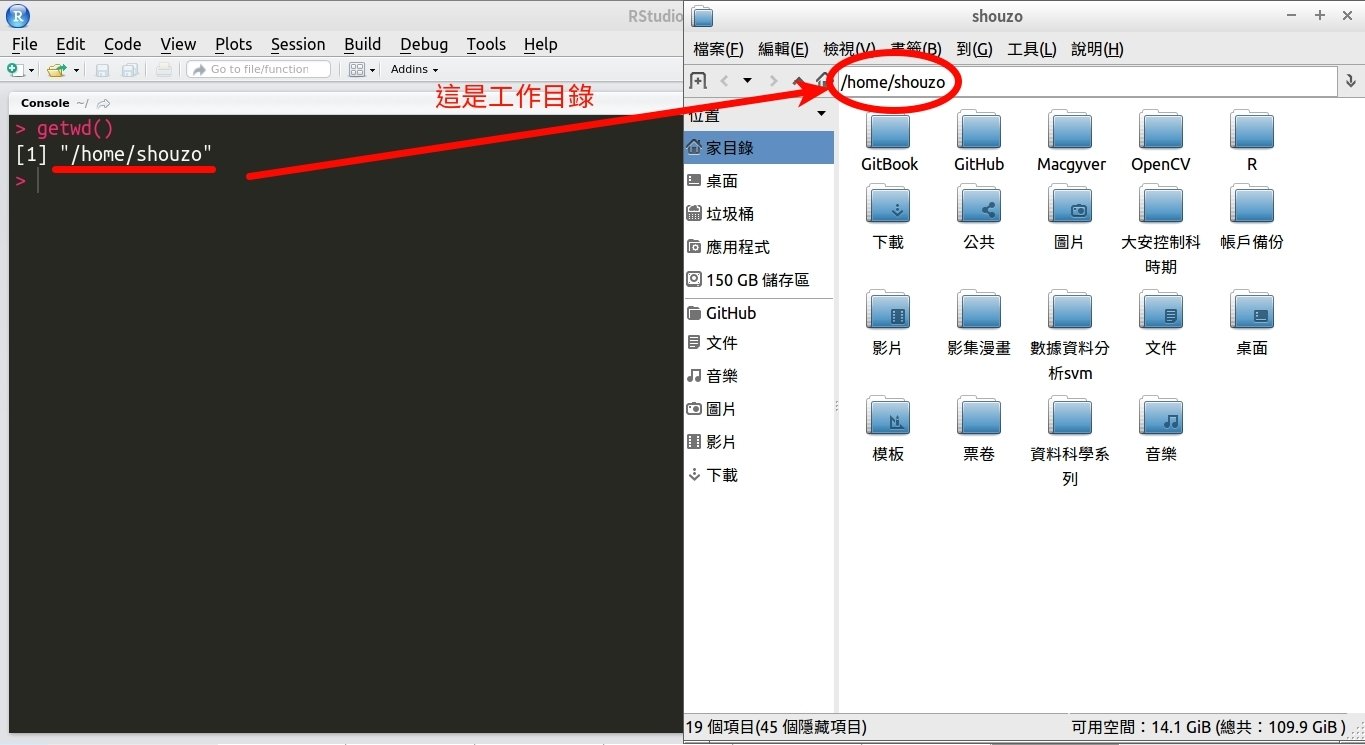
先取得目前的工作目錄
> getwd() # 輸入"getwd()"取得目前的工作目錄
[1] "/home/shouzo"
> 
2. 簡易視覺化
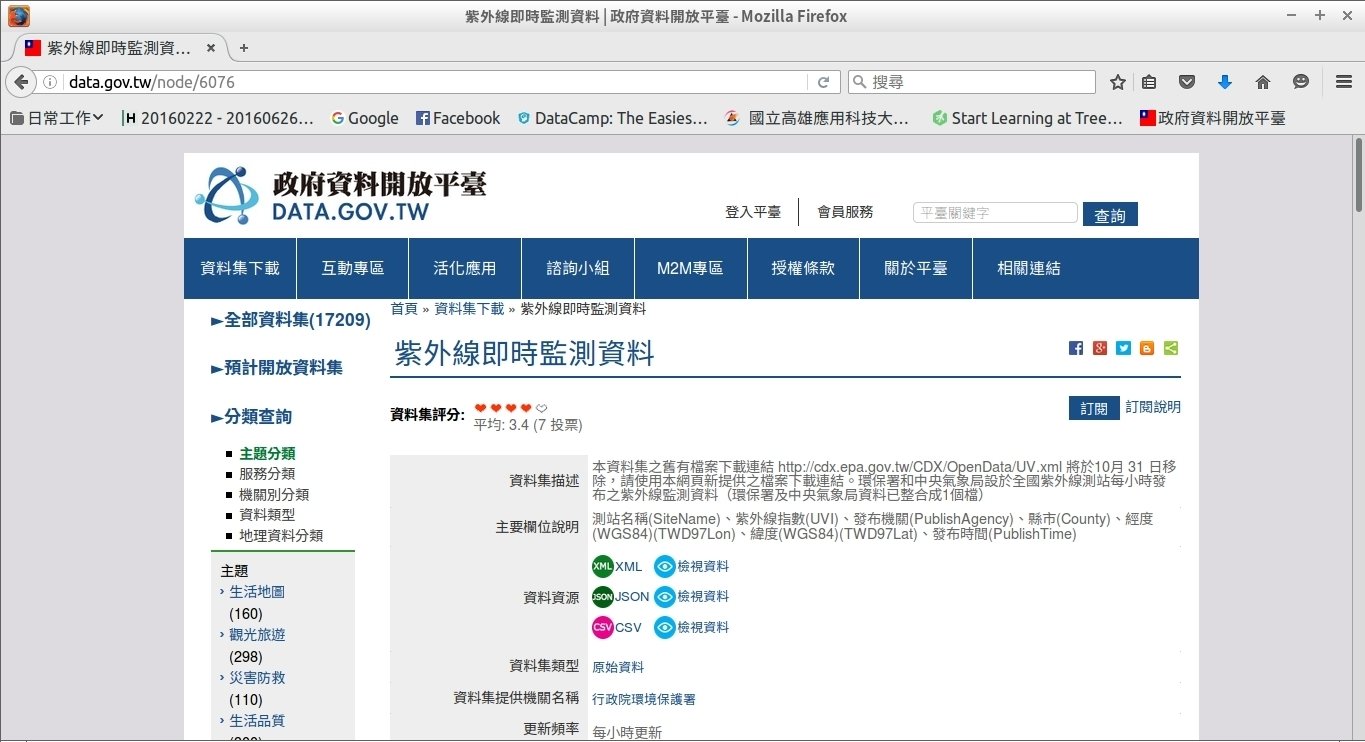
紫外線即時監測資料:http://data.gov.tw/node/6076
將資料存進工作目錄
STEP2:取得資料(2)
2. 簡易視覺化
載入並檢視資料
> # 載入要檢視的資料檔
> uv <- read.csv("UV_20160606120943.csv")
>
> head(uv) # 檢視資料檔的前半段資料
SiteName UVI PublishAgency County WGS84Lon WGS84Lat PublishTime
1 屏東 8 環境保護署 屏東縣 120,29,16.92 22,40,23.09 2016-06-06 12:00
2 橋頭 12 環境保護署 高雄市 120,18,20.48 22,45,27.02 2016-06-06 12:00
3 新營 3 環境保護署 臺南市 120,19,2.10 23,18,20.28 2016-06-06 12:00
4 朴子 5 環境保護署 嘉義縣 120,14,50.46 23,27,55.11 2016-06-06 12:00
5 塔塔加 7 環境保護署 嘉義縣 120,52,50.06 23,28,14.19 2016-06-06 12:00
6 阿里山 4 環境保護署 嘉義縣 120,48,05.02 23,30,30.82 2016-06-06 12:00
> STEP2:取得資料(3)
2. 簡易視覺化
STEP2:將資料進行處理
A. 進行經緯度的轉換
原始的經緯度資料是以度分秒表示,在使用前要轉換為度數表示。
> lon.deg <- sapply((strsplit(as.character(uv$WGS84Lon), ",")), as.numeric)
> uv$lon <- lon.deg[1, ] + lon.deg[2, ]/60 + lon.deg[3, ]/3600
> lat.deg <- sapply((strsplit(as.character(uv$WGS84Lat), ",")), as.numeric)
> uv$lat <- lat.deg[1, ] + lat.deg[2, ]/60 + lat.deg[3, ]/3600
> > ggmap(map) + geom_point(aes(x = lon, y = lat, size = UVI), data = uv)B. 把資料加入地圖中
2. 簡易視覺化
STEP3:輸出結果
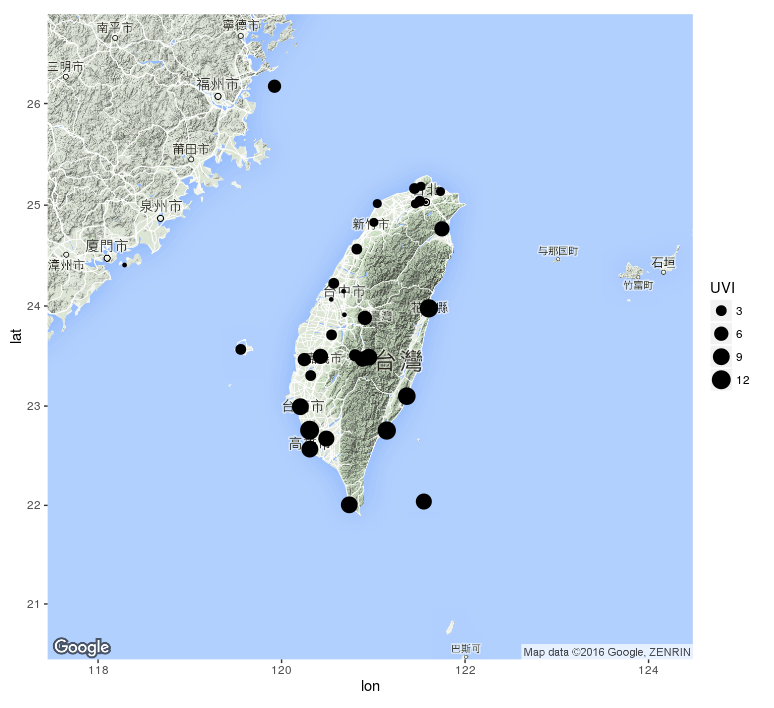
從結果圖中,我們可以得知全台灣在取得資料當下的紫外線分佈情況。
紫外線強度越大,點就會越大。
2. 簡易視覺化
3. 學習資源
資料科學 Data Science 系列 (3) - 資料探勘 (3)
3. 學習資源
R 語言翻轉教室
請自行完成以下的課程: