資料探勘 Data Mining (1)
基本觀念與工作環境的架設
資料科學 Data Science 系列 (1) - 資料探勘 (1)
姓名:羅左欣
日期:2016/5/23(一)
本著作係採用創用 CC 姓名標示-非商業性-相同方式分享 3.0 台灣 授權條款授權.

目錄 Contents
- 什麼是"資料探勘(Data Mining)"?
- 架設"工作環境(Workspace)"
- 實作"文字雲(Word Cloud)"
- 學習資源(自行練習)
資料科學 Data Science 系列 (1) - 資料探勘 (1)
資料科學 Data Science 系列 (1) - 資料探勘 (1)
1. 什麼是"資料探勘(Data Mining)"?
1. 什麼是"資料探勘(Data Mining)"?
它是"資料分析"技術裡的一個環節。
資料探勘 = 資料庫之知識發掘
(Knowledge Discovery in Databases,KDD)
亦可稱作
A. 數據挖掘
B. 資料挖掘
C. 資料採礦
目的:從大量的資料中提取"有價值的資訊"
1. 什麼是"資料探勘(Data Mining)"?
範例 A:商店、百貨公司 (營利機構)
設計出好的商品動線,吸引顧客購買商品。
資料探勘的應用...
範例 B:學校、補習班 (教育機構)
進行教學主題和模式上的調整,讓學生能夠提早進入狀況。
範例 C:醫院、診所 (醫療機構)
預測病患的嚴重程度,依據程度進行不同等級的處理,讓病患獲得妥善的照顧。(檢傷分類)
1. 什麼是"資料探勘(Data Mining)"?
資料探勘技術...
- 知識發掘(Knowledge Discovery):由現有的資料中,得知一些我們不知道的事情
- 假設檢定(Hypothesis Testing):嘗試去證實或舉反證來驗證預設的想法
分類
(Classification)
估計
(Estimation)
預測
(Predication)
關聯分析
(Association rule)
根據對象的屬性,分門別類加以定義。
根據現有屬性的資料,獲得新屬性未知的數值。
根據屬性之過去觀察值來推估該屬性未來之值。
從所有物件決定那些相關物件應該放在一起。
常見的技術:
集群
(Clustering)
將相關的資料聚集於各個群組之中,並分析群組間的差異。
資料科學 Data Science 系列 (1) - 資料探勘 (1)
2. 架設"工作環境(Workspace)"
2. 架設"工作環境(Workspace)"
在這個系列的簡報中,主要都會以 "R" 為資料探勘的示範軟體。

2. 架設"工作環境(Workspace)"
為什麼要使用 "R" ?
心裡悄悄話:因為我目前只會使用 "R"
免費、簡單、好用!
有說明文件、相關的網路論壇
可自行修改函式、套件包
跨平台使用
要學習撰寫腳本程式
使用時,需下載相關套件
不適合處理"大量數據"
需考慮套件版本與穩定性
優點
缺點
2. 架設"工作環境(Workspace)"
請點選下方網址,然後照著"YouTube"影片裡的步驟安裝 "R" 和 "RStudio"
以及所需的環境:

資料科學 Data Science 系列 (1) - 資料探勘 (1)
3. 實作"文字雲(Word Cloud)"
3. 實作"文字雲(Word Cloud)"
-
文字雲:
-
文字雲:
-
文字雲:
-
文字雲:
-
是"文字探勘"上常用的呈現手法之一
-
在資料裡出現次數越多的字詞,會加以突顯出來
-
比起表格類型的結果,文字雲更美觀
-
其他的特色等你用了就知道,記得要寫心得給我
特色...
3. 實作"文字雲(Word Cloud)"
-
文字雲:
-
文字雲:
-
文字雲:
-
文字雲:
-
文字雲:
-
準備要分析的資料(要求的檔案格式為".txt")
-
安裝和載入所需的套件
-
進行"文字探勘(Text Mining)"
-
製作"字詞矩陣(term-document matrix)"
-
產生"文字雲(Word Cloud)"
製作步驟...
3. 實作"文字雲(Word Cloud)"
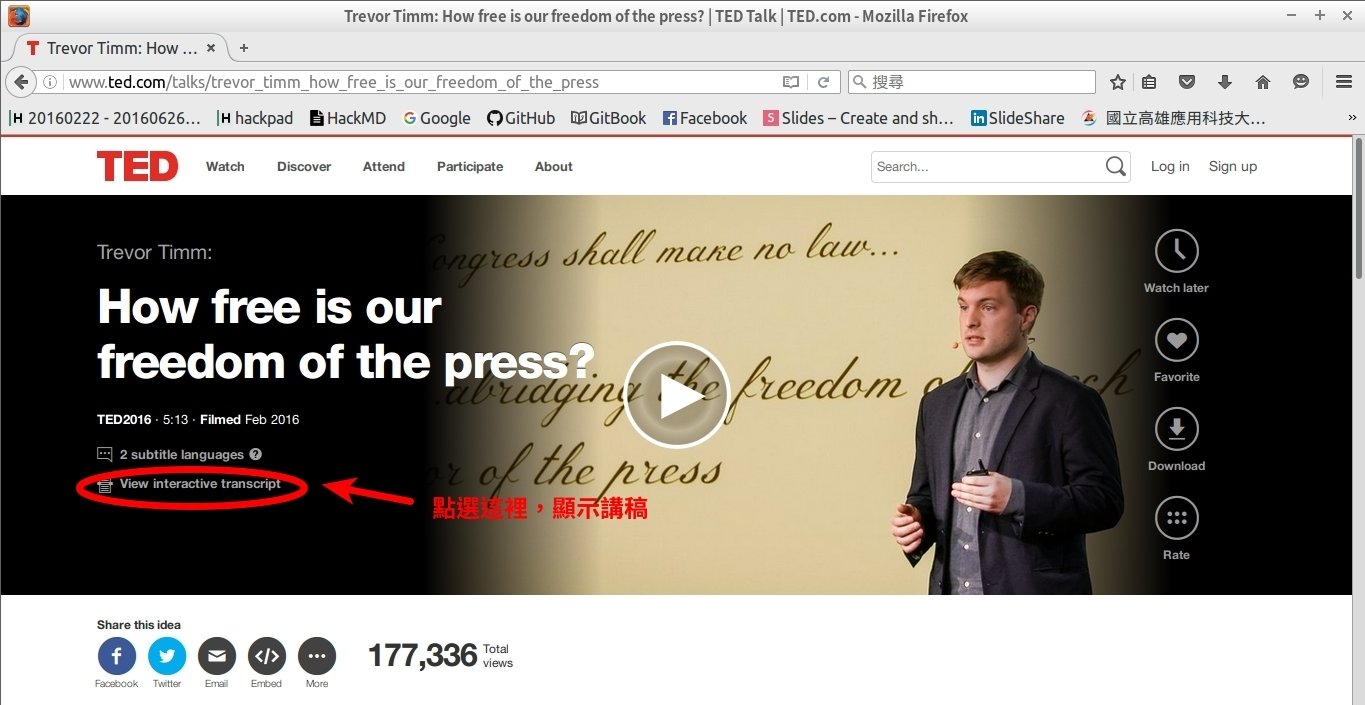
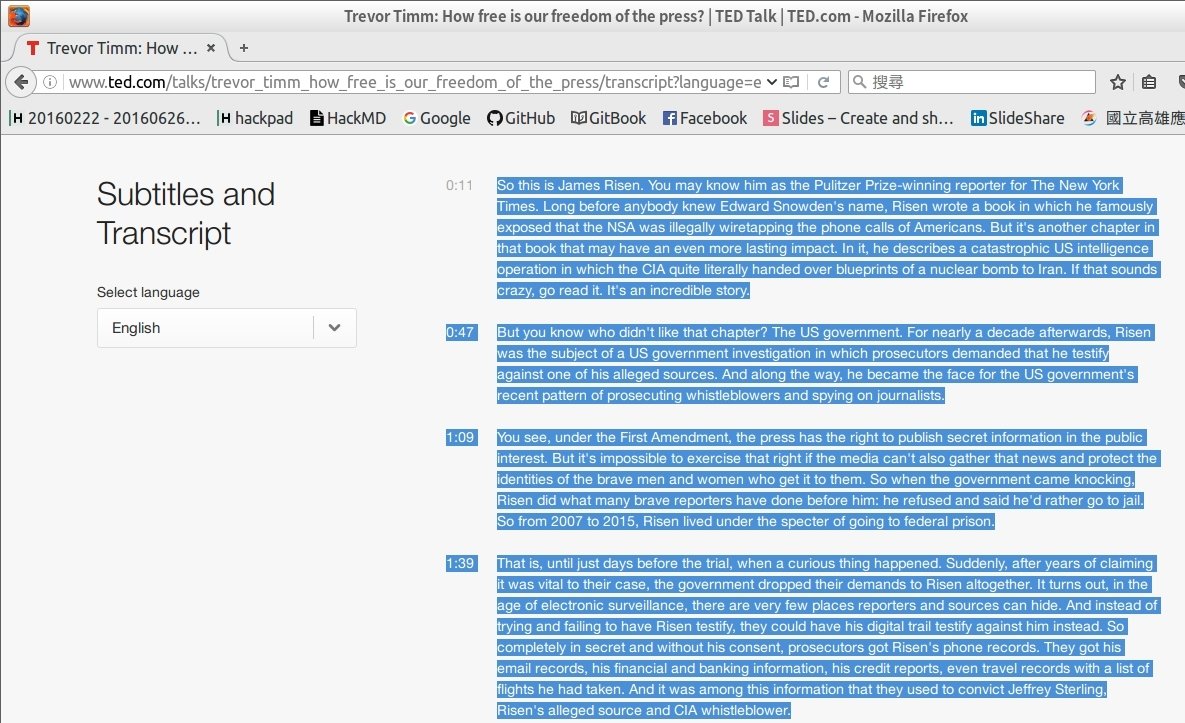
STEP 1:準備要分析的資料
在本次範例中,將選擇一篇TED網站上的演講搞來進行分析。
3. 實作"文字雲(Word Cloud)"
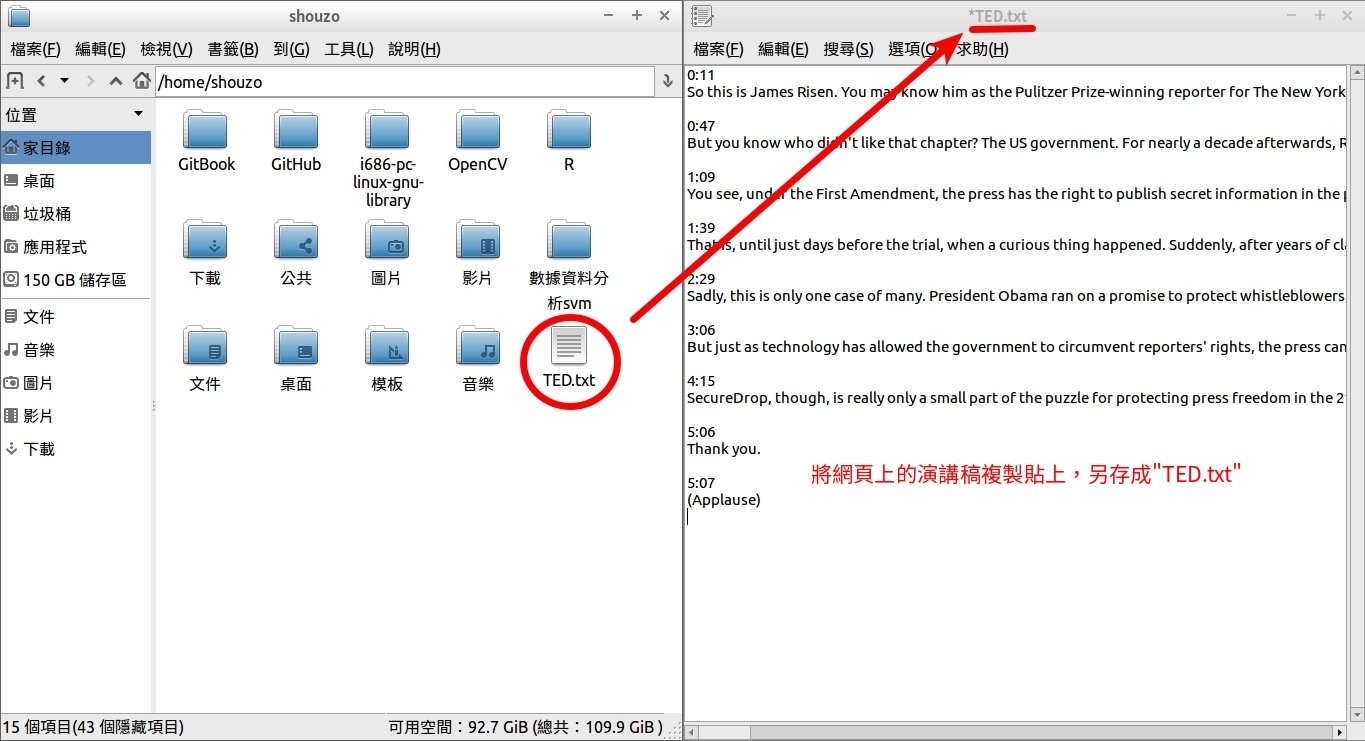
STEP 1:準備要分析的資料
將網頁上的演講稿內容全部複製之後,另存成 "TED.txt"。
3. 實作"文字雲(Word Cloud)"
STEP 2:安裝和載入所需的套件
# 安裝套件
install.packages("tm") # "文字探勘"用
install.packages("SnowballC") # Text stemming
install.packages("wordcloud") # 產生"文字雲"用
install.packages("RColorBrewer") # Color palettes
# 載入套件
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")開啟 RStudio,在命令列中輸入以下指令:
3. 實作"文字雲(Word Cloud)"
STEP 2:安裝和載入所需的套件
等待 RStudio 執行完畢:
3. 實作"文字雲(Word Cloud)"
STEP 3:進行"文字探勘(Text Mining)"
在命令列中輸入以下指令:
# 讀取 Text 檔案(.txt)
filePath <- ".../TED.txt" # 請將"..."改為"TED.txt"所在的目錄
text <- readLines(filePath)
# 將內容以"語料庫"的形式儲存
docs <- Corpus(VectorSource(text))3. 實作"文字雲(Word Cloud)"
STEP 3:進行"文字探勘(Text Mining)"
在命令列中輸入以下指令:
# 讀取 Text 檔案(.txt)
filePath <- ".../TED.txt" # 請將"..."改為"TED.txt"所在的目錄
text <- readLines(filePath)
# 將內容以"語料庫"的形式儲存
docs <- Corpus(VectorSource(text))
# 檢查內容
inspect(docs)
3. 實作"文字雲(Word Cloud)"
STEP 3:進行"文字探勘(Text Mining)"
在命令列中輸入以下指令:
# 讀取 Text 檔案(.txt)
filePath <- ".../TED.txt" # 請將"..."改為"TED.txt"所在的目錄
text <- readLines(filePath)
# 將內容以"語料庫"的形式儲存
docs <- Corpus(VectorSource(text))
# 檢查內容
inspect(docs)3. 實作"文字雲(Word Cloud)"
STEP 3:進行"文字探勘(Text Mining)"
- 過濾特殊字元:在命令列中輸入以下指令,將特殊字元以"空白"取代
# 將特殊的字元以"空白"取代
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
docs <- tm_map(docs, toSpace, "/") # 將"/"以"空白"取代
docs <- tm_map(docs, toSpace, "@") # 將"@"以"空白"取代
docs <- tm_map(docs, toSpace, "\\|") # 將"\\|"以"空白"取代- 過濾贅詞、符號:在命令列中輸入以下指令,移除贅詞和多餘的符號
# Convert the text to lower case
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeNumbers) # 移除數字
# 移除常見的"轉折詞彙"
docs <- tm_map(docs, removeWords, stopwords("english"))
docs <- tm_map(docs, removePunctuation) # 移除標點符號
docs <- tm_map(docs, stripWhitespace) # 移除額外的"空白"3. 實作"文字雲(Word Cloud)"
STEP 4:製作"字詞矩陣(term-document matrix)"
在命令列中輸入以下指令:
dtm <- TermDocumentMatrix(docs)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing = TRUE)
d <- data.frame(word = names(v),freq = v)
head(d, 10)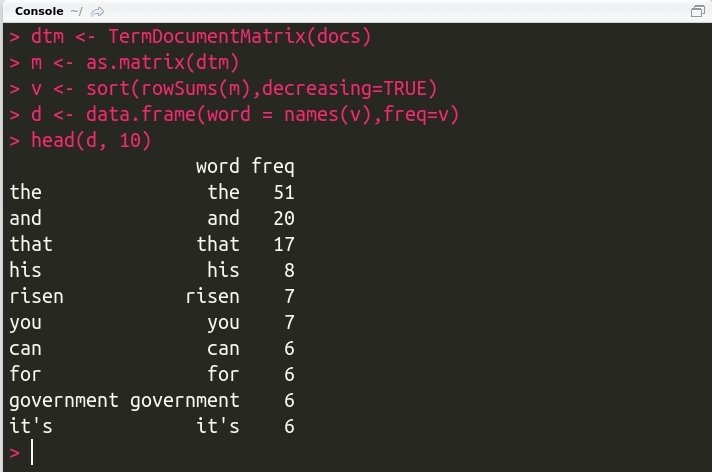
3. 實作"文字雲(Word Cloud)"
STEP 5:產生"文字雲(Word Cloud)"
在命令列中輸入以下指令:
set.seed(1000) # 設定可重複的亂數序列
wordcloud(words = d$word, freq = d$freq, min.freq = 3,
max.words = 100, random.order = FALSE, rot.per = 0.35,
colors=brewer.pal(8, "Dark2"))
產生的文字雲
資料科學 Data Science 系列 (1) - 資料探勘 (1)
4. 學習資源(自行練習)
4. 學習資源(自行練習)
R 語言翻轉教室
請自行完成以下的課程,之後會講解並應用這些課程上的內容: